Giới Thiệu
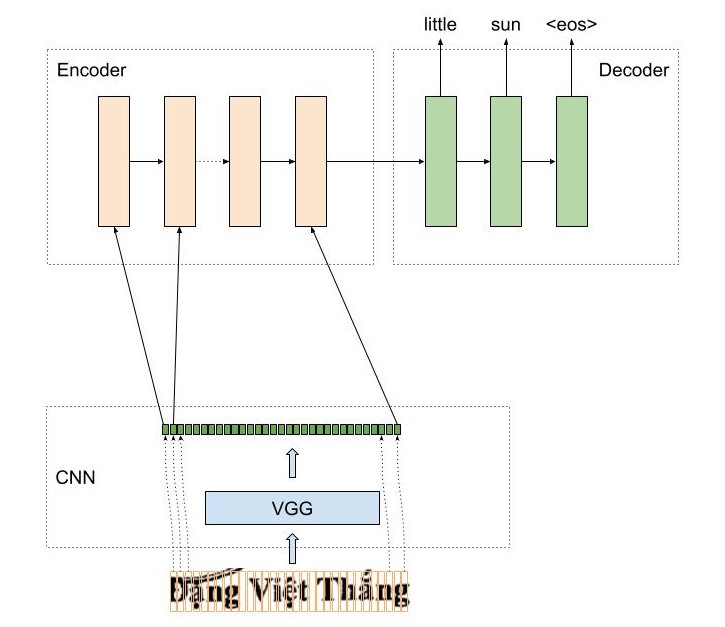
Trong blog này, mình chia sẻ một số thực nghiệm của 2 mô hình OCR cho bài toán nhận dạng chữ tiếng việt: AttentionOCR và TransformerOCR. AttentionOCR sử dụng kiến trúc attention seq2seq đã được sử dụng khá nhiều trong các bài toán NLP và cả OCR, còn TransformerOCR sử dụng kiến trúc của Transformer đã đạt được nhiều tiến bộ vượt bậc cho cộng đồng NLP. Một câu hỏi mà mình cũng khá quan tâm là Liệu TransformerOCR có mang lại kết quả vượt bậc như những gì các bạn đã nhìn thấy trong các bài toán NLP hay không ?
Đồng thời, mình cũng cung cấp một thư viện mới cho bài toán OCR, thư viện hướng tới kết quả chính xác, nhanh chóng, dễ huấn luyện, dễ dự đoán cho cả các bạn chưa có nhiều kinh nghiệm cũng có thể sử dụng được trong các bài toán liên quan đến số hóa.
Mô Hình
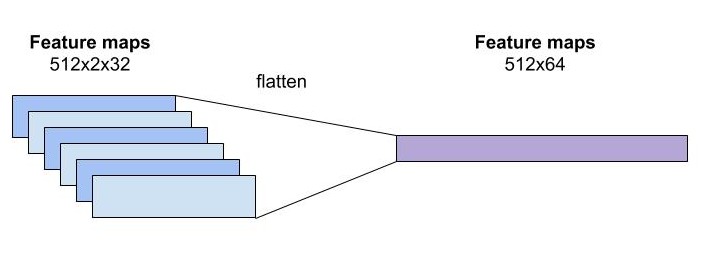
Mô hình CNN dùng trong bài toán OCR nhận đầu vào là một ảnh, thông thường có kích thước với chiều dài lớn hơn nhiều so với chiều rộng, do đó việc điều chỉnh tham số stride size của tầng pooling là cực kì quan trọng. Mình thường chọn kích thước stride size của các lớp pooling cuối cùng là wxh=2x1 trong mô hình OCR. Không thay đổi stride size phù hợp với kích thước ảnh thì sẽ dẫn đến kết quả nhận dạng của mô hình sẽ tệ. Đối với mô hình VGG, việc thay đổi pooling size khá dễ do kiến trúc đơn giản, tuy nhiên đối với mô hình phức tạp khác như resnet việc điều chỉnh tham số pooling size hơi phức tạp do một ảnh bị downsampling không chỉ bởi tầng pooling mà còn tại các tầng convolution khác. Trong pytorch, đối với mô hình VGG, các bạn chỉ đơn giản là thay thế stride size của tầng pooling.
cnn.features[i] = torch.nn.AvgPool2d(kernel_size=ks[pool_idx], stride=ss[pool_idx], padding=0)